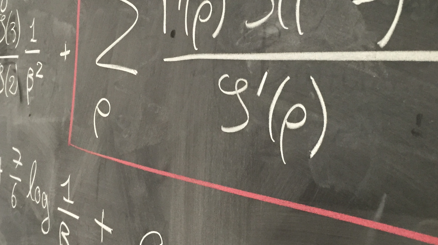Eloi Tanguy
Properties of Discrete Sliced Wasserstein Losses
The Sliced Wasserstein (SW) distance has become a common alternative to the Wasserstein distance for the comparison of probability measures. Widespread applications include image processing, domain adaptation and generative modelling, where it is typical to optimise some parameters in order to minimise SW, which serves as a loss function between discrete probability measures (since measures admitting densities are numerically unattainable). These optimisation problems all bear the same sub-problem, which is minimising the SW distance between two uniform discrete measures with the same amount of points as a function of the support (i.e. a matrix of data points) of one of the measures. We study the regularity and optimisation properties of this energy E, as well as its Monte-Carlo approximation E_p (estimating the expectation in SW using only p samples) and show convergence results on the critical points of E_p to those of E, as well as an almost-sure uniform convergence. Finally, we show that in a certain sense, Stochastic Gradient Descent methods minimising E and E_p converge towards (Clarke) critical points of these energies.